Unlocking AI Coding Assistants Part 3: Generating Diagrams, Open API Specs, And Test Data
Learn how to leverage AI assistants like LLMs to speed up development tasks such as generating UML diagrams, OpenAI specs, test data, and code.
Join the DZone community and get the full member experience.
Join For FreeWhile large language models (LLMs) offer valuable savings, automation, and time management, knowing and understanding their limitations—especially in defining relationships—and how to guide their output effectively can make a big difference. Let's dive into how you can make the most of LMMs in your every day development tasks. Enjoy!
Introduction
Part 3 of our Unlocking AI Assistants series explores how LLMs can support developers by generating UML diagrams, OpenAI specs, new features, and test data. You can find the first two articles below:
- Unlocking AI Coding Assistants Part 1: Real-World Use Cases
- Unlocking AI Coding Assistants Part 2: Generating Code
Some tasks are executed with the help of an AI coding assistant. The responses are evaluated and different techniques are applied, which can be used to improve the responses when necessary.
The tasks are executed with the IntelliJ IDEA DevoxxGenie AI coding assistant.
The setup used in this blog is LMStudio as inference engine and qwen2.5-coder:7b as model. This runs on GPU.
The sources used in this blog are available at GitHub.
Prerequisites
Prerequisites for reading this blog are:
- Basis coding knowledge.
- Basic knowledge of AI coding assistants.
- Basic knowledge of DevoxxGenie. For more information, you can read my previous blog, ''DevoxxGenie: Your AI Assistant for IntelliJ IDEA," or watch the conference talk given at Devoxx.
Task: Generate PlantUML from SQL
The goal is to see whether AI can be helpful in generating a PlantUML diagram from a PostgreSQL schema. The PostgreSQL schema is taken from the Spring PetClinic. The goal is to create a database diagram according to Information Engineering Diagrams.
Prompt
Open the file and enter the prompt.
create a plantuml file from this code using Information Engineering DiagramsResponse
The response can be viewed here.
Response Analysis
The generated diagram looks as follows.

The response is quite good: the tables are correct and the diagram is drawn according to the Information Engineering Diagrams. However, some issues exist:
- The primary and foreign keys are not shown.
- The relations are incomplete.
- The relations are defined in the wrong direction.
Prompt
Let's try to solve the primary and foreign keys issue first. Enter the prompt.
the primary and foreign keys are not shown in the tables and they are mandatoryResponse
The response can be viewed here.
Response Analysis
The generated diagram looks as follows.

The response did improve:
- The primary and foreign keys are added now.
- Only the foreign keys are mandatory, not the primary keys. The primary keys should have been marked as mandatory too.
Prompt
Let's try to fix the relations. Enter the prompt.
Not all relations are drawn and the cardinality seems to be the other way around.Response
The response can be viewed here.
Response Analysis
The generated diagram looks as follows.

This dis not make any significant difference.
Prompt
Let's try to be more specific. Enter the prompt.
The relations between owners and pets, and between owners and types are missing.Response
The response can be viewed here.
Response Analysis
The generated diagram looks as follows.

The missing relations are added, but still in the wrong direction and with a slightly different syntax than in the Information Engineering Diagrams.
Prompt
Which result can we achieve when using an online LLM like Anthropic Claude 3.5 Sonnet?
Open a new chat window and enter the prompt.
create a plantuml file from this code using Information Engineering DiagramsResponse
The response can be viewed here.
Response Analysis
The generated diagram looks as follows.
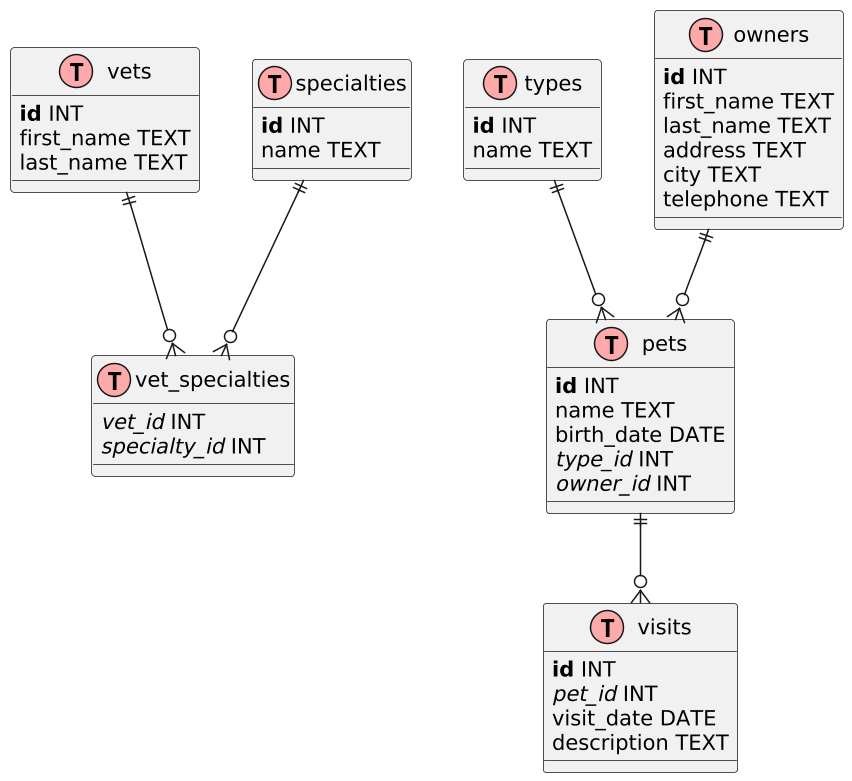
This seems to be a better result, only the Information Engineering Diagrams notation is not used.
Prompt
It seems that Claude 3.5 Sonnet does not know about the Information Engineering Diagram syntax. Let's give some additional instructions in the prompt.
the IE notation is not used. The IE notation is as follows:
This extension adds:
Additional relations for the Information Engineering notation;
An entity alias that maps to the class diagram class;
An additional visibility modifier * to identify mandatory attributes.
Otherwise, the syntax for drawing diagrams is the same as for class diagrams. All other features of class diagrams are also supported.
Example:
===
@startuml
' hide the spot
' hide circle
' avoid problems with angled crows feet
skinparam linetype ortho
entity "User" as e01 {
*user_id : number <<generated>>
--
*name : text
description : text
}
entity "Card" as e02 {
*card_id : number <<generated>>
sync_enabled: boolean
version: number
last_sync_version: number
--
*user_id : number <<FK>>
other_details : text
}
entity "CardHistory" as e05 {
*card_history_id : number <<generated>>
version : number
--
*card_id : number <<FK>>
other_details : text
}
entity "CardsAccounts" as e04 {
*id : number <<generated>>
--
card_id : number <<FK>>
account_id : number <<FK>>
other_details : text
}
entity "Account" as e03 {
*account_id : number <<generated>>
--
user_id : number <<FK>>
other_details : text
}
entity "Stream" as e06 {
*id : number <<generated>>
version: number
searchingText: string
--
owner_id : number <<FK>>
follower_id : number <<FK>>
card_id: number <<FK>>
other_details : text
}
e01 }|..|| e02
e01 }|..|| e03
e02 }|..|| e05
e02 }|..|| e04
e03 }|..|| e04
e02 }|..|| e06
e03 }|..|| e06
@enduml
===Response
The response can be viewed here.
Response Analysis
The generated diagram looks as follows.

The diagram is quite okay:
- The
hide circleshould be commented out to make it more IE syntax; - The relations are not correct;
- The instructions are followed, but even for Claude 3.5 Sonnet the relations are too complex to draw.
End Conclusion
Both offline and online LLMs are able to generate the tables correctly. Both have problems with the relations.
Some techniques for improving the response are used:
- Point out the errors in the response to the LLM.
- Use examples.
- Use a different model.
- Try to give clearer instructions.
Task: Generate PlantUML Class Diagram
The goal is to see whether AI can be helpful in generating a PlantUML Class diagram. Maybe this is easier to do for an LLM.
The Refactor code package will be used for drawing the diagram.
Prompt
Add the source directory to the Prompt Context. Enter the prompt.
Generate a plantuml class diagram for this codeResponse
The response can be viewed here.
Response Analysis
The generated diagram looks as follows.

The response is quite good, but also some issues exist:
- The relations for the
Refactorclass are incomplete. ClassesRefactorMessage,SingleDataDto,MultiDataDto, etc. are also used. - The double relations between
BaseMessageandLocationMessage,MultiDataMessage,SingleDataMessageare not correct. This should be a single relation. - Methods and class variables are correct.
- The visibility of methods in class
Refactoris not correct. Only themainmethod has public visibility and the others should be private. DataTypeis an enum and should have been marked as an enum.
Prompt
These issues seem to be quite similar as for the task to generate a PlantUML from SQL.
We know from Part 1 of this blog that AI coding assistants are good at reviewing code. So let's see whether the issues can be found.
Enter the prompt.
Review the plant uml and give suggestions in order to improve it. It should ressemble the provided code.Response
The response can be viewed here.
Response Analysis
The suggested improved version looks as follows.

Some general suggestions are given. However, the only difference with the previous version, is that the relationship between RefactorMessage and DataRepository, MessageService has a label "uses."
To conclude, the classes are generated correctly besides the visibility. This saves you a lot of time already. The relations, visibility, etc. needs to be added or corrected after reviewing the PlantUML.
Task: Generate OpenAPI Specification
The goal is to see whether AI can be helpful in generating an OpenAPI Specification.
Prompt
Enter the prompt.
Generate an OpenAPI specification version 3.1.1.
The spec should contain CRUD methods for customers.
The customers have a first name and a last name.
Use the Zalando restful api guidelines.Response
The response can be viewed here.
Response Analysis
This is quite amazing. With only very limited information, a valid OpenAPI specification is created and this really makes sense.
The list of customers should have the ID's included in the response, but this is something you can easily add yourself.
Task: Generate Feature
The goal is to see whether AI can be helpful in generating a new feature.
The Spring PetClinic will be used to add a new feature. The starting point is this branch. In the Spring PetClinic, you can search for owners.

You can search for all owners, which shows a paginated list of owners. But, you can also search for a single owner, which shows the details of that owner.

Now you would like to have similar functionality for finding pets.
With the GPU-setup, it was not possible to add the entire source directory to the prompt due to the hardware limit. Instead, this task is executed by means of Anthropic using model Claude 3.5 Sonnet.
Prompt
Add the entire project to the Prompt Context and enter the prompt.
create a search pet functionality, similar as searching for owners, generate the code for itResponse
The response can be viewed here.
Response Analysis
The suggested changes seem to be okay. They are applied in this branch.
After applying these changes, you also need to format the files, otherwise the Spring PetClinic cannot be built.
$ mvn spring-javaformat:applyHowever, when you run the application and click the "Find Pets" menu item, an exception occurs.
Prompt
Copy the exception and enter the prompt.
the following error occurs:
```
2025-02-01T11:31:46.013+01:00 ERROR 29216 --- [nio-8080-exec-3] org.thymeleaf.TemplateEngine : [THYMELEAF][http-nio-8080-exec-3] Exception processing template "pets/petsList": Exception evaluating SpringEL expression: "pet.owner.id" (template: "pets/petsList" - line 22, col 10)
org.thymeleaf.exceptions.TemplateProcessingException: Exception evaluating SpringEL expression: "pet.owner.id" (template: "pets/petsList" - line 22, col 10)
```Response
The response can be viewed here.
Response Analysis
When you apply the suggested fixes and run the application, again an exception occurs.
Prompt
Copy the exception and enter the prompt.
the following error occurs
```
Caused by: org.hibernate.query.sqm.UnknownPathException: Could not resolve attribute 'owner' of 'org.springframework.samples.petclinic.owner.Pet' [SELECT DISTINCT pet FROM Pet pet LEFT JOIN FETCH pet.owner WHERE LOWER(pet.name) LIKE LOWER(CONCAT('%', :name, '%'))]
at org.hibernate.query.hql.internal.StandardHqlTranslator.translate(StandardHqlTranslator.java:88) ~[hibernate-core-6.6.2.Final.jar:6.6.2.Final]
at org.hibernate.query.internal.QueryInterpretationCacheStandardImpl.createHqlInterpretation(QueryInterpretationCacheStandardImpl.java:145) ~[hibernate-core-6.6.2.Final.jar:6.6.2.Final]
at org.hibernate.query.internal.QueryInterpretationCacheStandardImpl.resolveHqlInterpretation(QueryInterpretationCacheStandardImpl.java:132) ~[hibernate-core-6.6.2.Final.jar:6.6.2.Final]
at org.hibernate.query.spi.QueryEngine.interpretHql(QueryEngine.java:54) ~[hibernate-core-6.6.2.Final.jar:6.6.2.Final]
at org.hibernate.internal.AbstractSharedSessionContract.interpretHql(AbstractSharedSessionContract.java:831) ~[hibernate-core-6.6.2.Final.jar:6.6.2.Final]
at org.hibernate.internal.AbstractSharedSessionContract.createQuery(AbstractSharedSessionContract.java:877) ~[hibernate-core-6.6.2.Final.jar:6.6.2.Final]
... 57 common frames omitted
```Response
The response can be viewed here.
Response Analysis
The suggested changes seem to be okay. These are applied in this branch.
This time, the functionality is working as expected.
A new menu item is added.
You can find all pets, which results in a paginated list of pets.

You can find a single pet, which returns the item in the list because there is no pet detail page.

Findings
Are we able to create a new feature using AI? Well, yes, it was successful in the end, after a few iterations.
We did hit the limit of a local LLM and the hardware.
Task: Generate Test Data
The goal is to see whether AI can be helpful in generating test data.
The final solution branch of the Spring PetClinic generating a feature is used.
The setup using PostgreSQL is needed. Some actions need to be taken for this.
- Run the PostgreSQL database. Start the following command from within the root of the repository.
docker compose up -d- Copy the contents of
src/main/resources/application-postgres.propertiesand replace the following line insrc/main/resources/application.properties:
database=h2- Run the Spring PetClinic.
$ mvn spring-boot:runPrompt
Add file postgres-schema.sql to the Prompt Context and enter the prompt.
Generate test data which can be inserted by means of SQL commands in a postgres databaseResponse
The response can be viewed here.
Response Analysis
Using a visual check, this seems to be okay. But, as they say, the proof of the pudding is in the eating, so let's use the data.
- Shut down the Spring PetClinic and PostgreSQL container (
docker compose down). - Copy the suggested test data in file
src/main/resources/db/postgres/data.sql - Start the PostgreSQL container and Spring Boot application.
The test data is correct and complete.
Prompt
Let's see whether we can make the test data more specific and add some more criteria.
Start a new chat window and add the file again to the Prompt Context. Enter the prompt.
Generate test data which can be inserted by means of SQL commands in a postgres database.
I want at least 5 vets, 30 owners, 10 different types of pets.
Each owner must have at least one pet, some owners have more than one pet.Response
The response can be viewed here.
Response Analysis
This is a mediocre response and incomplete.
- Five vets are added.
- Nine different types of pets are added instead of 10.
- One owner is added with one pet.
- A second owner is added with two pets.
- The pet names are not very creative (Pet1, Pet2, Pet3). Same applies to the owners.
After this, some tests were performed using a higher temperature, but the SQL statements were not correct anymore and the data was incomplete.
Prompt
Let's try to split it up into smaller tasks.
First, let's create the vets. Start a new chat window and add the file to the Prompt Context. Enter the prompt.
Generate test data which can be inserted by means of SQL commands in a postgres database.
I want at least 5 vets, exactly three specialties and every vet must have at least one specialtyResponse
The response can be viewed here.
Response Analysis
The vets, specialties and vet specialties are created as asked. This is good.
Prompt
Let's create the type of pets.
Start a new chat window and add the file to the Prompt Context. Enter the prompt.
Generate test data which can be inserted by means of SQL commands in a postgres database.
I want 10 different types of pets. Nothing else needs to be generated.Response
The response can be viewed here.
Response Analysis
This response was remarkably faster than the previous one. Ten pet types are provided.
Prompt
Let's create 30 owners.
Start a new chat window and add the file to the Prompt Context. Enter the prompt.
Generate test data which can be inserted by means of SQL commands in a postgres database.
I want 30 owners. Nothing else needs to be generated.Response
The response can be viewed here.
Response Analysis
A total of 29 owners are provided, one is missing, but the data seems to be okay.
Prompt
Let's create at least one pet for each owner.
All data is gathered in file large-data-without-pets.sql.
Start a new chat window and add the schema file and the SQL file from above to the Prompt Context. Enter the prompt.
Generate test data which can be inserted by means of SQL commands in a postgres database.
The data in large-data-without-pets.sql is already available.
Generate for each owner at least one pet. Nothing else needs to be generated.Response
The response can be viewed here.
Response Analysis
Fifty pets are created. However, owner IDs higher than 29 are used, even up to and including 50. When you omit these, or assign them to existing owners, the data is usable.
File large-data-with-pets.sql contains a fixed version where pets are assigned to existing owners.
Prompt
The only thing we are missing are some visits.
Start a new chat window and add the schema file and the sql file from above to the Prompt Context. Enter the prompt.
Generate test data which can be inserted by means of SQL commands in a postgres database.
The data in large-data-with-pets.sql is already available.
Generate 20 visits. Nothing else needs to be generated.Response
The response can be viewed here.
Response Analysis
The LLM created 20 visits for the first 20 pets. It is not very creative because it just took the first 20 pets, but it did what was asked.
The data is gathered in file large-data-with-visits.sql. Copy and paste it in the data.sql file of the Spring PetClinic. Start the database container and the Spring PetClinic application. All data is available for use.
Generating test data with an LLM can save you a lot of time. Depending on the capabilities of your LLM, it is wise to split it into smaller tasks for better results.
Conclusion
From the examples used in this blog, the following conclusions can be drawn:
- Using an LLM to generate UML diagrams can save you time. Tables or classes are generated correctly; the relations, you need to specify yourself. An LLM is not good at generating the relations.
- Using an LLM to generate an OpenAPI specification works just fine. It can help you generate a correct OpenAPI spec. After this, you can tweak it yourself, but this is already a great time saver.
- When generating a feature, we hit the hardware limit of the local LLM. Using a cloud LLM, it was possible to generate code for a new feature. Some iterations were needed, but in the end, it just worked.
- An LLM can be used to generate test data. It is wise to split the task into smaller tasks for better results. This is actually also how you would generate test data when you have to do it manually. So this applies to LLMs also.
- Some techniques you can apply in order to improve the responses are:
- Explain to the LLM what is wrong with the response.
- Use examples.
- Use a different model.
- Try to give clearer instructions or use different phrasing.
Opinions expressed by DZone contributors are their own.
Comments